
kubernetes网络原理
1.单机容器网络实现的原理
网络栈:网卡,回环设备,路由表,iptables ,这些要素构成了它发起响应网络请求的基本环境
容器可以直接使用宿主机的网络栈(-net=host)
docker run -d -net=host --name nginx-host nginx
这种情况,容器直接是使用的是宿主机的80端口
直接使用宿主机的网络栈的方式很简单,但是会带来资源共享的问题,比如端口冲突
那么被隔离的一个容器进程如何跟其它NetWork Namspace里的容器进行通信呢?
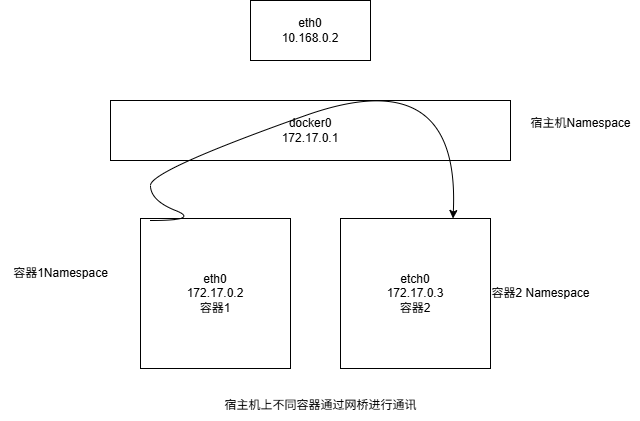
在linux中,能够起到虚拟交换机作用的设备是网桥(bridge),它是一个数据链路层,docker 项目会默认的在宿主机上创建一个docker0网桥,容器通过docker0网桥进行通信
容器通过Veth Pair的虚拟设备连接到docker0网桥
1 | # 在宿主机上 |
可以看到,容器里面有一个eth0网卡,它正是一个Veth Pair,查看路由表,,这个eth0网卡容器里面的默认路由规则,所有的对172.17.0.0/16网段请求,也都会由 eth0来处理
在宿主机上:
1 | charlie@master:~$ ip addr |
查看、创建和管理软件桥接设备,我们可以看到 nginx-1容器对应的Veth Pair设置在宿主机上是一个虚拟网卡
1 | charlie@master:~$ docker run -d --name nginx-2 nginx |
此时如果在 nginx-1 容器里面 ping nginx-2 的地址,你就会发现同一台宿主机上 两个容器默认相互连通,其原理很简单,nginx-1容器访问nginx-2里的IP地址。,这个目标IP地址会匹配到nginx-1容器里面的第二条路由规则,这个路由规则的网关是0.0.0.0,这是一条直连规则。通过二层网络,达到nginx-2容器,就需要nginx-2的iP的MAC地址。nginx-1容器通过eth0网卡发送一个ARP广播查找MAC地址
ARP:是通过三层的IP地址找到了第二层的MAC地址的协议
具体的处理ARP请求,以及docker0如何链接nginx-2网络协议,以及怎样找到对应的mac地址我这里不做介绍
1.宿主机上不同的容器通过网桥进行通信
2.容器访问其它宿主机
同样的道理,当一个容器试图链接其它宿主机的时候,如ping 10.168.0.3 它首先通过docker0网桥,然后根据宿主机里面的路由规则,对请求的访问就会交个宿主机的etch0处理 ,请求流程如下:
容器1—-> 宿主机的docker0-> 宿主机1eth0 —> 宿主机的2 etch0
3.如何访问另一台主机上的容器
一台宿主机上docker0网桥和其它宿主机上的docker0没有关联,所以要通过一个“公用”的网桥,然后把集群里的所有容器都链接到这个网桥上。构建容器网络的核心在于,需要在宿主机上的网络上通过软件构建一个可以把所有容器都连通起来的虚拟网络, 这种技术就是 覆盖网络
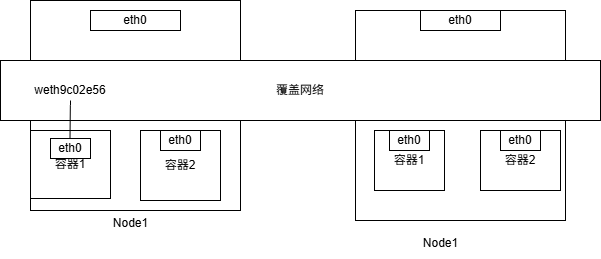
2.深入理解容器跨主机网络
要理”解跨主通信”,就一定要从Flannnel这个项目上说起,Flannel项目是CoreOs公司推出的容器网络解决方案,目前Flannel支持三种后端的实现
- VXLAN
- host-gw
- UDP
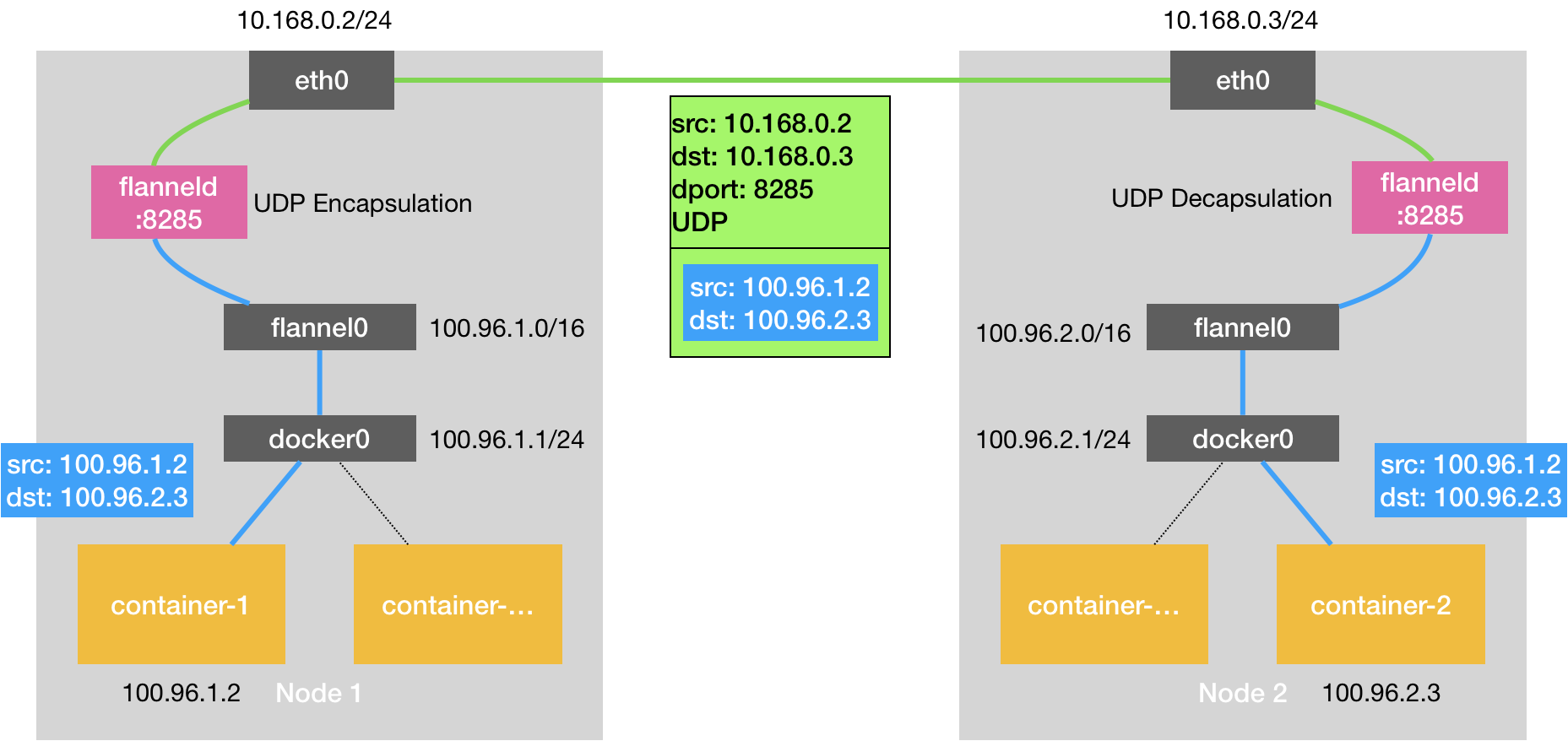
UDP是最简单的实现,也是性能最差的,Flannel UDP模式提供的就是一个三层覆盖网络,它首先对发出端的IP包进行UPD封装,然后在接受端进行解封,拿到原始的IP包,接着把这个IP包转发给目标容器。就好比Flannel 在不同宿主机的两个容器上打通了一个“隧道”,似的两个容器可以直接用IP通信,无需关注宿主机和容器的分布情况,相比两台主机直接通信,基于Flannel UDP模式多了一个额外的步骤,FlannelId的处理过程。
数据包会先被 Flannel 的
flanneld守护进程捕获。flanneld将原始数据包封装在 UDP 数据包中,外层头部的源/目的 IP 是宿主机的 IP 地址。封装后的 UDP 包通过宿主机的网络栈发送到目标节点。
flanneld 进程在处理由 flannel0 传入的 IP 包时,就可以根据目的 IP 的地址(比如 100.96.2.3),匹配到对应的子网(比如 100.96.2.0/24),从 Etcd 中找到这个子网对应的宿主机的 IP 地址是 10.168.0.3
https://juejin.cn/post/7246279539986546746?searchId=202505161030531BC232DF0DA23450235A
我们在进行系统级编程的时候,有一个非常重要的优化原则,就是要减少用户态到内核态的切换次数,并且把核心的处理逻辑都放在内核态进行。这也是为什么,Flannel 后来支持的VXLAN 模式,逐渐成为了主流的容器网络方案的原因。
Flannel 是 Kubernetes 中常用的 CNI(容器网络接口)插件之一,主要用于为集群中的 Pod 提供网络通信能力。Flannel 支持多种后端(Backend)模式,其中 UDP 和 VXLAN 是两种常见的数据包封装和传输方式。以下是它们的工作原理和区别:
- Flannel UDP 模式
工作原理
- 封装与解封装:
- 当 Pod A 发送数据包到另一个节点上的 Pod B 时,数据包会先被 Flannel 的
flanneld守护进程捕获。 flanneld将原始数据包封装在 UDP 数据包中,外层头部的源/目的 IP 是宿主机的 IP 地址。- 封装后的 UDP 包通过宿主机的网络栈发送到目标节点。
- 当 Pod A 发送数据包到另一个节点上的 Pod B 时,数据包会先被 Flannel 的
- 传输过程:
- 数据包经过宿主机的网络协议栈和物理网络,到达目标节点的 UDP 端口(默认
8285)。 - 目标节点的
flanneld解封装 UDP 包,提取原始数据包,并将其注入目标 Pod 的网络命名空间。
- 数据包经过宿主机的网络协议栈和物理网络,到达目标节点的 UDP 端口(默认
- 性能特点:
- 用户态处理:封装/解封装由用户态的
flanneld完成,涉及多次内核态与用户态切换(copy-to-user/copy-to-kernel),性能较差。 - 兼容性高:适用于不支持内核级封装的旧环境。
- 用户态处理:封装/解封装由用户态的
缺点
- 高开销:UDP 封装和用户态处理导致高 CPU 开销。
- 低效:不适合高吞吐量场景。
所以说,我们在进行系统级编程的时候,有一个非常重要的优化原则,就是要减少用户态到内核态的切换次数,并且把核心的处理逻辑都放在内核态进行。这也是为什么,Flannel 后来支持的VXLAN 模式,逐渐成为了主流的容器网络方案的原因。
Flannel VXLAN 模式
VXLAN,即 Virtual Extensible LAN(虚拟可扩展局域网),是 Linux 内核本身就支持的一种网络虚似化技术。所以说,VXLAN 可以完全在内核态实现上述封装和解封装的工作,从而通过与前面相似的“隧道”机制,构建出覆盖网络(Overlay Network)。
VXLAN 的覆盖网络的设计思想是:在现有的三层网络之上,“覆盖”一层虚拟的、由内核 VXLAN 模块负责维护的二层网络,使得连接在这个 VXLAN 二层网络上的“主机”(虚拟机或者容器都可以)之间,可以像在同一个局域网(LAN)里那样自由通信。当然,实际上,这些“主机”可能分布在不同的宿主机上,甚至是分布在不同的物理机房里。
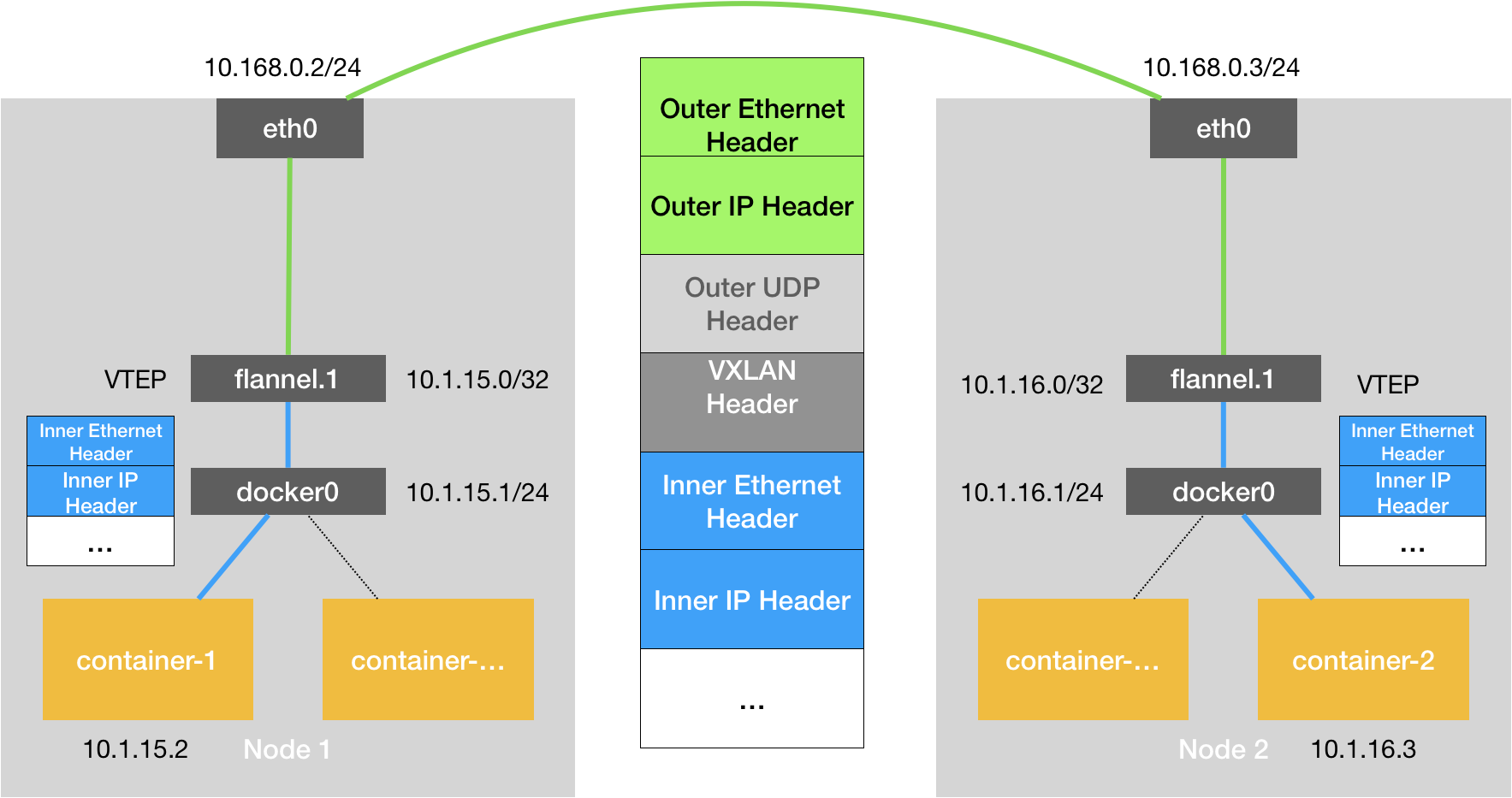
工作原理
- VXLAN是Linux内核支持的网络虚拟化技术,可以在内核态实现封装和解封装工作。
- VXLAN在现有三层网络之上覆盖一层虚拟的二层网络,使连接在VXLAN二层网络上的主机(虚拟机或容器)可以像在同一个局域网内自由通信。
VXLAN通信流程:
- 容器发出的IP包通过docker网桥进入宿主机。
- IP包被路由到VTEP设备(flannel.)。
- VTEP设备将IP包封装成二层数据帧,并根据ARP记录找到目的VTEP设备的MAC地址。
- Linux内核将二层数据帧进一步封装成UDP包,并通过宿主机网络发送给目的宿主机。
- 目的宿主机接收UDP包,拆包得到二层数据帧,再根据VNI值交给对应的VTEP设备。
- VTEP设备拆包得到原始IP包,并发送给对应的容器。
关键组件:
- VTEP(VXLAN Tunnel End Point):虚拟隧道端点,负责封装和解封装二层数据帧。
- VNI(Virtual Network Identifier):虚拟网络标识符,用于标识VXLAN网络。
- FDB(Forwarding Database):转发数据库,记录VTEP设备之间的转发规则。
封装与解封装:
- VXLAN(Virtual Extensible LAN)是 L2 over L4 的隧道技术,通过 内核模块 实现封装(使用 UDP 端口
8472)。 - 当 Pod A 发送数据包时,内核的 VXLAN 模块将原始数据包封装为 VXLAN 格式:
- 外层 UDP 头:源/目的端口为
8472。 - 外层 IP 头:源/目的 IP 是宿主机的 IP。
- VXLAN 头:包含 VNI(VXLAN Network Identifier,默认为
1)。
- 外层 UDP 头:源/目的端口为
- VXLAN(Virtual Extensible LAN)是 L2 over L4 的隧道技术,通过 内核模块 实现封装(使用 UDP 端口
传输过程:
- 封装后的 VXLAN 包通过物理网络到达目标节点。
- 目标节点的内核 VXLAN 模块解封装数据包,并根据 VNI 和 MAC 地址将数据包转发到目标 Pod。
性能特点:
- 内核态处理:封装/解封装由内核完成,避免用户态切换,性能显著优于 UDP 模式。
- 广播与多播:VXLAN 支持广播/多播(Flannel 通常使用单播模式)。
两种子模式
- VXLAN(默认):使用内核的 L3 路由,无需学习 MAC 地址(类似“无脑转发”)。
- DirectRouting:若节点在同一子网,直接通过主机网络通信(跳过 VXLAN 封装),进一步提升性能。
优点
- 高性能:内核级封装,吞吐量高。
- 可扩展:支持大规模集群。
kubernetes 网络模型与CNI网络插件
介绍了容器跨主机的两种方案,UDP,和VXLAN,他们都有一个共性,用户的容器都是链接到docker0网桥上,不过kubernetes是通过CNI的接口维护了一个单独的网桥来代替 docker0
CNI(Container Network Interface)网络插件的原理是通过标准化的接口和配置文件,实现容器网络接口的动态创建、配置和管理。其核心机制可概括为以下四部分:
一、*标准化接口与配置文件*
CNI定义了一套JSON格式的网络配置文件,描述网络参数(如IP地址分配、网桥名称、路由规则等)。容器运行时(如kubelet、containerd)通过环境变量和标准输入传递配置文件,调用CNI插件执行操作。例如:
1 | { |
此配置文件指定了使用bridge插件创建网桥cni0,并通过host-local插件分配IP地址。
二、*插件类型与职责*
CNI插件分为两类:
- 接口插件(Interface Plugin):负责创建网络接口,如
bridge、macvlan,直接管理容器的网络命名空间。 - 链式插件(Chained Plugin):对已有接口进行二次配置,如
portmap(端口映射)、firewall(防火墙规则)。
例如,bridge插件创建网桥后,portmap插件可为其添加端口映射规则。
三、*操作流程*
CNI插件支持四种操作,通过环境变量CNI_COMMAND触发:
- Add:创建网络接口并配置IP、路由等,返回分配的IP和路由信息。
- Del:删除网络接口及关联配置,逆向操作
Add。 - Check:验证网络配置是否有效,若失败则触发容器重启。
- Version:返回插件支持的CNI版本。
操作流程中,插件通过标准输入接收配置文件,执行后通过标准输出返回结果。链式调用时,前序插件的输出(prevResult)会作为后序插件的输入。
四、*链式调用与扩展性*
单个插件功能单一,复杂场景需组合多个插件。CNI通过plugins数组定义执行顺序,例如:
1 | { |
此配置先创建网桥,再映射端口,最终通过libcni库自动处理配置转换和结果传递。
有两篇不错的介绍 CNI插件原理的文章
https://mp.weixin.qq.com/s/V7ItqZ-ACiXHwq9pAr48Kg
https://mp.weixin.qq.com/s/M484q0_vHPnkyULvkZBIQg
CNI的核心原理是通过标准化配置文件和插件化架构,实现容器网络的动态管理。其优势在于解耦网络方案与容器平台,支持灵活扩展(如Flannel的VXLAN覆盖网络、Calico的BGP路由)。实际应用中,Kubernetes等平台依赖CNI插件(如kube-flannel、cilium)实现Pod间跨主机通信。
- Pod 启动 → Kubelet 通过 CRI 调用容器运行时;
- 容器运行时调用 CNI 插件 → 传入 JSON 配置和容器命名空间等信息;
- 插件为容器创建网络接口 → 如 veth 对、分配 IP、设置路由;
- 完成网络接入 → 插件返回结果,容器正式接入网络;
- Pod 删除时 → 插件执行 DEL 操作,释放 IP 和清理网络资源。
在 Kubernetes 中,Kubelet 利用容器运行时(如 Containerd、CRI-O)来调用 CNI 插件。具体流程为:
- Kubelet 在创建 Pod 时通过 CRI 向容器运行时发送请求创建 Pod 沙箱。
- 容器运行时在宿主机上首先为 Pod 创建一个新的网络命名空间(NetNS),然后执行 CNI 插件的
ADD操作。 - 容器运行时将 Pod 的网络命名空间路径、Pod 名称、UID 等信息通过环境变量传递给 CNI 插件(如
CNI_NETNS、CNI_ARGS),并将 CNI 配置 JSON 通过标准输入提供给插件。 - CNI 插件在收到
CNI_COMMAND=ADD后,在对应命名空间内创建虚拟网卡(通常是一对 veth 设备)并配置 IP/路由,然后将网卡连接到宿主机上的桥接或隧道等网络设备。 - 配置完成后,插件将结果(如分配的 IP)返回给运行时,Kubelet 得到成功信号后启动 Pod 主进程。
- Pod 删除时,Kubelet 会删除 Pod,对应运行时调用 CNI 插件的
DEL操作清理网络配置。
解读kubernetes 的三层网络方案
Flannel 的 host-gw 模式的工作原理
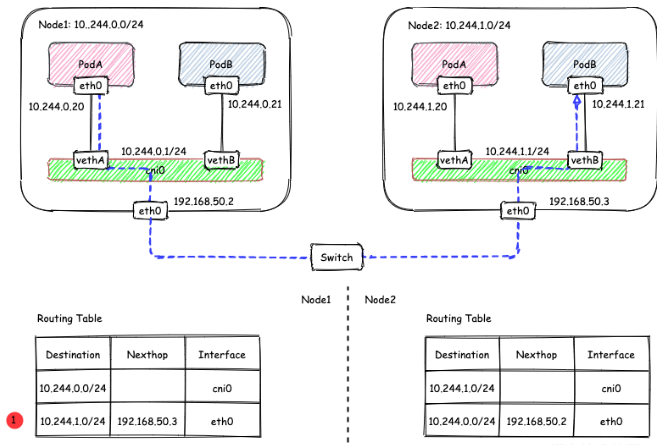
1 | ip route |
这条路由规则的含义是: 目前IP地址数据 10.244.1.0/24网段的IP包经过本机的eth0s设设备(dev eth0)出发,并且它的吓一跳地址是 192.168.50.3
我的理解。host-gw模式的工作原理其实就是将每个Flannel子网的下一跳设置成了该子网对应的宿主机的IP地址。也就是说这台“主机”会充当这条容器通信路径的 “网关”,这就是 “host-gw”的含义
Calico 项目
https://docs.tigera.io/calico/latest/about/
Calico is a networking and security solution that enables Kubernetes workloads and non-Kubernetes/legacy workloads to communicate seamlessly and securely.
参考资料:
https://mp.weixin.qq.com/s/t6Wg0aKDMP1aTGDVQ_vSqA
《深入剖析kubernetes》–张磊
Calico 是一种网络和安全解决方案,可让 Kubernetes 工作负载和非 Kubernetes/旧版工作负载无缝且安全地进行通信。
实际上,Calico提供的网络解决方案与 Flannel host-gw模式几乎完全一样 ,也就是说Calico也会在每一台宿主机上添加一条路由规则
1 | <目的容器IP地址段> via <网关的IP地址> dev eth0 |
网关的IP地址就是容器所在的路由地址,三层网络方案的核心,是为了每个容器IP地址找到对应的下一个跳的网关
Calico项目使用BGP(边界网关协议)
BGP是一个 Linux内核原生支持的,专门用与大规模数据中心维护不同的自治系统(AS)之间路由信息,无中心的路由协议。
Felix:运行在每一台 Host 的 agent 进程,主要负责网络接口管理和监听、路由、ARP 管理、ACL 管理和同步、状态上报等。etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;BGP Client(BIRD):Calico 为每一台 Host 部署一个 BGP Client,使用 BIRD 实现,BIRD 是一个单独的持续发展的项目,实现了众多动态路由协议比如 BGP、OSPF、RIP 等。在 Calico 的角色是监听 Host 上由 Felix 注入的路由信息,然后通过 BGP 协议广播告诉剩余 Host 节点,从而实现网络互通。
BGP(
Kubernetes Calico 网络插件原理总结
Calico 是 Kubernetes 中广泛使用的 网络与网络策略插件,基于 纯三层(Layer 3)路由 实现高性能、低延迟的 Pod 间通信,并支持强大的网络策略(NetworkPolicy)。其核心原理如下:
(1) IP 分配与路由
- IPAM(IP 地址管理):
Calico 为每个 Pod 分配唯一的 IP 地址(通常来自配置的 IP 池,如192.168.0.0/16),并确保无冲突。 - 路由表配置:
每个节点上的Felix会:- 为本地 Pod 创建路由规则(如
192.168.1.2 dev caliXXX)。 - 通过 BGP 协议将路由信息广播给其他节点(例如:
192.168.1.0/24 via <Node2-IP>)。
- 为本地 Pod 创建路由规则(如
(2) 数据包转发(纯三层)
- 同节点 Pod 通信:
直接通过 Linux 内核路由表和veth pair设备转发(无需封装)。 - 跨节点 Pod 通信:
数据包通过节点的物理网卡发出,经底层网络(如云厂商 VPC 或物理交换机)直接路由到目标节点,无需隧道封装(如 VXLAN)。- 优势:低延迟、高性能(无隧道开销)。
- 要求:底层网络需支持节点间路由(例如云厂商 VPC 或 BGP 配置)。
(3) 网络策略(NetworkPolicy)
- 基于 iptables/eBPF:
Calico 将 Kubernetes 的NetworkPolicy转换为 iptables 或 eBPF 规则,实现精细化的流量控制(如允许/拒绝特定 Pod 的访问)。 - 示例规则:
1
2# 查看 Calico 生成的 iptables 规则
iptables -L -n -v | grep cali
3. 关键模式
(1) BGP 模式(默认)
- 原理:节点间通过 BGP 协议交换路由信息,要求底层网络支持 BGP 或直连路由。
- 适用场景:
- 自建数据中心(物理机或虚拟机)。
- 云厂商支持 BGP 的环境(如 AWS 的 Direct Connect)。
(2) IP-in-IP 模式
- 原理:跨节点通信时,Calico 对数据包封装 IP-in-IP 头部(外层 IP 为节点 IP)。
- 适用场景:
- 底层网络不支持 BGP(如某些云环境)。
- 需要跨子网通信但无法配置路由表。
VXLAN 模式
- 原理:通过 VXLAN 隧道封装跨节点流量(类似 Flannel 的 VXLAN 后端)。
- 适用场景:
- 无法使用 BGP 或 IP-in-IP 的环境(如某些受限网络)。
- 需要兼容 Overlay 网络的场景。
4. 性能优化特性
| 特性 | 说明 |
|---|---|
| eBPF 加速 | 替代 iptables,提升网络策略处理性能(需内核 >= 4.18)。 |
| WireGuard | 支持加密 Pod 间流量(可选)。 |
| ECMP 路由 | 通过等价多路径路由提升带宽利用率(需底层网络支持)。 |
5. 与其他插件的对比
| 特性 | Calico | Flannel | Cilium |
|---|---|---|---|
| 网络模型 | 三层路由(BGP/IP-in-IP/VXLAN) | Overlay(VXLAN/UDP) | eBPF + Overlay |
| 性能 | 高(无封装或轻量封装) | 中(VXLAN 开销) | 高(eBPF 加速) |
| 网络策略 | 支持 | 需配合其他插件(如 Cilium) | 原生支持 |
| 适用场景 | 需要高性能和策略的生产环境 | 简单 Overlay 网络 | 需要高级观测和安全性 |
6. 总结
- 核心优势:
- 高性能(纯三层路由,无隧道开销)。
- 强大的网络策略(基于 iptables/eBPF)。
- 灵活的路由模式(BGP/IP-in-IP/VXLAN)。
- 适用场景:
- 生产环境(尤其是需要网络策略和低延迟的集群)。
- 自建数据中心或云厂商支持 BGP 的环境。
- 推荐配置:
- 默认使用 BGP 模式(若底层支持)。
- 启用 eBPF 替代 iptables(内核 >= 4.18)。
通过 Calico,Kubernetes 集群可以获得接近物理网络的性能,同时满足企业级的安全性和策略需求。
- 本文作者: 东方觉主
- 本文链接: http://www.charon193.com/2025/05/13/k8snet/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!